
나의 잡다한 노트 및 메모
Loki 아키텍처 본문
아키텍쳐
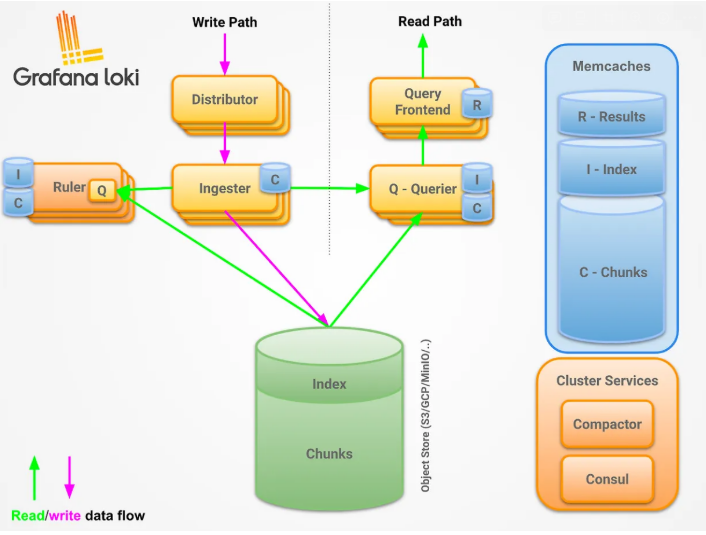
- Read Path와 Write Path : Loki는 로그 데이터 처리를 위한 읽기 경로와 쓰기 경로를 구분한다. 이러한 분리는 데이터 처리의 효율성을 극대화하며, 각 경로는 특정 작업에 최적화된 컴포넌트로 구성된다.
- Consistent Hash Rings : 클러스터 내에서 데이터를 균등하게 분배하고 고가용성을 보장하는 메커니즘이다. 이는 클러스터의 스케일링을 용이하게 하며, 데이터 샤딩과 복제를 통한 안정성을 제공한다.
- Multi tenancy : Loki는 multi tenancy를 지원하여, 하나의 Loki 인스턴스를 여러 사용자나 팀이 공유할 수 있게 한다. 이는 리소스의 효율적인 사용과 데이터 분리를 가능하게 한다.
Write Path

로그 스트림이 장기 저장소에 저장되는 과정
Distributor
클라이언트로부터 받은 스트림을 처리하여 Ingester로 전달하는 중요한 역할을 한다.
- 주요 기능 및 특징
- 유효성 검사(Validation)
- 전처리 (Preprocessing) : 스트림의 레이블을 정렬하는 과정. 이를 통해 효율적으로 캐시하고 해시할 수 있다.
- 속도 제한(Rate limiting) : 테넌트별 최대 전송률을 설정.
- 전달 (Forwarding) : 유효성 검사와 전처리 작업을 마친 후, 데이터는 Ingester로 전달된다. Ingester는 최종적으로 데이터의 쓰기를 승인하며, 이 과정에서 replication_factor를 참고하여 복제본을 생성한다.
- 해싱 (Hashing) : 일관된 해싱을 사용해 특정 스트림이 전달될 Ingester 인스턴스를 결정한다. 이는 데이터가 올바른 대상에게 전달되도록 한다.
- 쿼럼 일관성(Quorum consistency) : Distributor는 최소 절반 이상의 Ingester로부터 응답을 받기 전까지는 클라이언트에게 응답을 보류한다.
Ingester
로그 데이터를 장기 저장소 백엔드에 저장하고, 필요 시 인메모리 쿼리를 통해 데이터를 빠르게 검색하는 역할을 한다.
- 주요 기능 및 특징
- 수명 주기 관리 : Ingester 내에는 lifecycler라 불리는 컴포넌트가 있어, 해시 링을 통해 각 Ingester의 생명 주기를 관리한다. Ingester의 상태는 PENDING, JOINING, ACTIVE, LEAVING, UNHEALTHY 중 하나이다.
- 청크 처리 : 로그 스트림은 메모리 내에서 여러 청크 집합으로 관리되며, 설정 가능한 주기에 따라 장기 저장소 백엔드로 플러시된다. 청크는 플러시가 발생할 때 압축되고 읽기 전용으로 전환된다.
- 데이터 복제 : 플러시되지 않은 데이터 손실을 방지하기 위해 로그 데이터를 여러 iNGESTER에 복제한다.
- Timestamp Ordering : 설정을 통해 시간 순서가 뒤섞인 데이터 쓰기를 허용할 수 있다. 설정이 없으면 오류로 반환.
Read Path
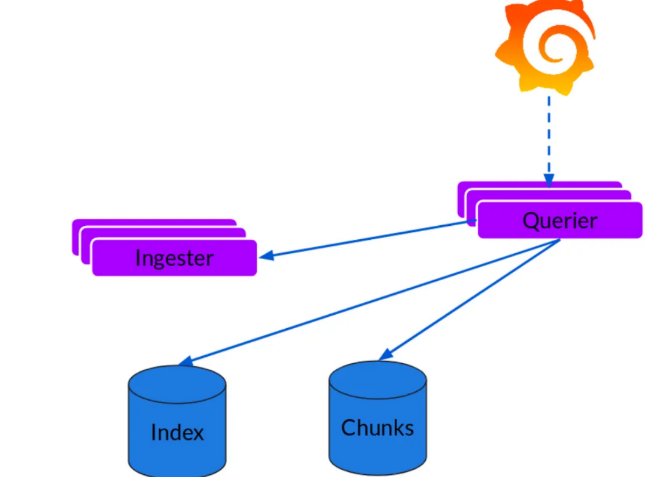
로그 스트림이 장기 저장소에 읽어지는 과정
Query Frontend
실제 쿼리를 실행하는 Querier를 보조하여 읽기 경로의 성능을 향상시키는 서비스.
아래와 같은 기능을 수행한다.
- 큐잉(Queueing): 큰 쿼리로 인한 메모리 부족 문제를 방지하고, 공정한 스케줄링을 가능하게 합니다. 이는 더 작은 쿼리의 병렬 실행을 통해 전체 소유 비용(TCO)을 줄이는 데 기여합니다.
- 분할(Splitting): 큰 쿼리를 여러 작은 쿼리로 분할하여 Querier의 메모리 부족 문제를 예방하고, 쿼리 결과를 더 빠르게 도출할 수 있도록 합니다.
- 캐싱(Caching): 쿼리 결과를 캐시하여 후속 쿼리에서 재사용합니다. 이는 쿼리 수행 시간을 단축시키고 전반적인 시스템 성능을 향상시키는 데 도움이 됩니다.
Querier
LogQL 쿼리 언어를 사용하여 로그 데이터에 대한 쿼리를 처리한다.
주요 기능은 아래와 같다.
- 인메모리 데이터 및 장기 저장소 쿼리: 모든 Ingester에서 현재 메모리에 있는 데이터를 쿼리한 다음, 같은 쿼리를 장기 저장소에 대해서도 실행합니다. 이는 실시간 데이터와 과거 데이터 모두에 대한 쿼리를 가능하게 합니다.
- 중복 제거: 복제로 인해 중복된 데이터를 수신할 수 있는데, Querier는 동일한 나노초 타임스탬프, 레이블 세트 및 로그 메시지를 가진 데이터를 중복 제거하여 최종 쿼리 결과의 정확성을 보장합니다.아키텍쳐
- Read Path와 Write Path : Loki는 로그 데이터 처리를 위한 읽기 경로와 쓰기 경로를 구분한다. 이러한 분리는 데이터 처리의 효율성을 극대화하며, 각 경로는 특정 작업에 최적화된 컴포넌트로 구성된다.
- Consistent Hash Rings : 클러스터 내에서 데이터를 균등하게 분배하고 고가용성을 보장하는 메커니즘이다. 이는 클러스터의 스케일링을 용이하게 하며, 데이터 샤딩과 복제를 통한 안정성을 제공한다.
- Multi tenancy : Loki는 multi tenancy를 지원하여, 하나의 Loki 인스턴스를 여러 사용자나 팀이 공유할 수 있게 한다. 이는 리소스의 효율적인 사용과 데이터 분리를 가능하게 한다.
Write Path
 클라이언트로부터 받은 스트림을 처리하여 Ingester로 전달하는 중요한 역할을 한다.
클라이언트로부터 받은 스트림을 처리하여 Ingester로 전달하는 중요한 역할을 한다.
- 주요 기능 및 특징
- 유효성 검사(Validation)
- 전처리 (Preprocessing) : 스트림의 레이블을 정렬하는 과정. 이를 통해 효율적으로 캐시하고 해시할 수 있다.
- 속도 제한(Rate limiting) : 테넌트별 최대 전송률을 설정.
- 전달 (Forwarding) : 유효성 검사와 전처리 작업을 마친 후, 데이터는 Ingester로 전달된다. Ingester는 최종적으로 데이터의 쓰기를 승인하며, 이 과정에서 replication_factor를 참고하여 복제본을 생성한다.
- 해싱 (Hashing) : 일관된 해싱을 사용해 특정 스트림이 전달될 Ingester 인스턴스를 결정한다. 이는 데이터가 올바른 대상에게 전달되도록 한다.
- 쿼럼 일관성(Quorum consistency) : Distributor는 최소 절반 이상의 Ingester로부터 응답을 받기 전까지는 클라이언트에게 응답을 보류한다.
- 주요 기능 및 특징
- 수명 주기 관리 : Ingester 내에는 lifecycler라 불리는 컴포넌트가 있어, 해시 링을 통해 각 Ingester의 생명 주기를 관리한다. Ingester의 상태는 PENDING, JOINING, ACTIVE, LEAVING, UNHEALTHY 중 하나이다.
- 청크 처리 : 로그 스트림은 메모리 내에서 여러 청크 집합으로 관리되며, 설정 가능한 주기에 따라 장기 저장소 백엔드로 플러시된다. 청크는 플러시가 발생할 때 압축되고 읽기 전용으로 전환된다.
- 데이터 복제 : 플러시되지 않은 데이터 손실을 방지하기 위해 로그 데이터를 여러 iNGESTER에 복제한다.
- Timestamp Ordering : 설정을 통해 시간 순서가 뒤섞인 데이터 쓰기를 허용할 수 있다. 설정이 없으면 오류로 반환.
Read Path
 실제 쿼리를 실행하는 Querier를 보조하여 읽기 경로의 성능을 향상시키는 서비스.
실제 쿼리를 실행하는 Querier를 보조하여 읽기 경로의 성능을 향상시키는 서비스.
- 큐잉(Queueing): 큰 쿼리로 인한 메모리 부족 문제를 방지하고, 공정한 스케줄링을 가능하게 합니다. 이는 더 작은 쿼리의 병렬 실행을 통해 전체 소유 비용(TCO)을 줄이는 데 기여합니다.
- 분할(Splitting): 큰 쿼리를 여러 작은 쿼리로 분할하여 Querier의 메모리 부족 문제를 예방하고, 쿼리 결과를 더 빠르게 도출할 수 있도록 합니다.
- 캐싱(Caching): 쿼리 결과를 캐시하여 후속 쿼리에서 재사용합니다. 이는 쿼리 수행 시간을 단축시키고 전반적인 시스템 성능을 향상시키는 데 도움이 됩니다.
- 인메모리 데이터 및 장기 저장소 쿼리: 모든 Ingester에서 현재 메모리에 있는 데이터를 쿼리한 다음, 같은 쿼리를 장기 저장소에 대해서도 실행합니다. 이는 실시간 데이터와 과거 데이터 모두에 대한 쿼리를 가능하게 합니다.
- 중복 제거: 복제로 인해 중복된 데이터를 수신할 수 있는데, Querier는 동일한 나노초 타임스탬프, 레이블 세트 및 로그 메시지를 가진 데이터를 중복 제거하여 최종 쿼리 결과의 정확성을 보장합니다.아키텍쳐
- Read Path와 Write Path : Loki는 로그 데이터 처리를 위한 읽기 경로와 쓰기 경로를 구분한다. 이러한 분리는 데이터 처리의 효율성을 극대화하며, 각 경로는 특정 작업에 최적화된 컴포넌트로 구성된다.
- Consistent Hash Rings : 클러스터 내에서 데이터를 균등하게 분배하고 고가용성을 보장하는 메커니즘이다. 이는 클러스터의 스케일링을 용이하게 하며, 데이터 샤딩과 복제를 통한 안정성을 제공한다.
- Multi tenancy : Loki는 multi tenancy를 지원하여, 하나의 Loki 인스턴스를 여러 사용자나 팀이 공유할 수 있게 한다. 이는 리소스의 효율적인 사용과 데이터 분리를 가능하게 한다.
Write Path
클라이언트로부터 받은 스트림을 처리하여 Ingester로 전달하는 중요한 역할을 한다.
- 주요 기능 및 특징
- 유효성 검사(Validation)
- 전처리 (Preprocessing) : 스트림의 레이블을 정렬하는 과정. 이를 통해 효율적으로 캐시하고 해시할 수 있다.
- 속도 제한(Rate limiting) : 테넌트별 최대 전송률을 설정.
- 전달 (Forwarding) : 유효성 검사와 전처리 작업을 마친 후, 데이터는 Ingester로 전달된다. Ingester는 최종적으로 데이터의 쓰기를 승인하며, 이 과정에서 replication_factor를 참고하여 복제본을 생성한다.
- 해싱 (Hashing) : 일관된 해싱을 사용해 특정 스트림이 전달될 Ingester 인스턴스를 결정한다. 이는 데이터가 올바른 대상에게 전달되도록 한다.
- 쿼럼 일관성(Quorum consistency) : Distributor는 최소 절반 이상의 Ingester로부터 응답을 받기 전까지는 클라이언트에게 응답을 보류한다.
- 주요 기능 및 특징
- 수명 주기 관리 : Ingester 내에는 lifecycler라 불리는 컴포넌트가 있어, 해시 링을 통해 각 Ingester의 생명 주기를 관리한다. Ingester의 상태는 PENDING, JOINING, ACTIVE, LEAVING, UNHEALTHY 중 하나이다.
- 청크 처리 : 로그 스트림은 메모리 내에서 여러 청크 집합으로 관리되며, 설정 가능한 주기에 따라 장기 저장소 백엔드로 플러시된다. 청크는 플러시가 발생할 때 압축되고 읽기 전용으로 전환된다.
- 데이터 복제 : 플러시되지 않은 데이터 손실을 방지하기 위해 로그 데이터를 여러 iNGESTER에 복제한다.
- Timestamp Ordering : 설정을 통해 시간 순서가 뒤섞인 데이터 쓰기를 허용할 수 있다. 설정이 없으면 오류로 반환.
Read Path
실제 쿼리를 실행하는 Querier를 보조하여 읽기 경로의 성능을 향상시키는 서비스.
- 큐잉(Queueing): 큰 쿼리로 인한 메모리 부족 문제를 방지하고, 공정한 스케줄링을 가능하게 합니다. 이는 더 작은 쿼리의 병렬 실행을 통해 전체 소유 비용(TCO)을 줄이는 데 기여합니다.
- 분할(Splitting): 큰 쿼리를 여러 작은 쿼리로 분할하여 Querier의 메모리 부족 문제를 예방하고, 쿼리 결과를 더 빠르게 도출할 수 있도록 합니다.
- 캐싱(Caching): 쿼리 결과를 캐시하여 후속 쿼리에서 재사용합니다. 이는 쿼리 수행 시간을 단축시키고 전반적인 시스템 성능을 향상시키는 데 도움이 됩니다.
- 인메모리 데이터 및 장기 저장소 쿼리: 모든 Ingester에서 현재 메모리에 있는 데이터를 쿼리한 다음, 같은 쿼리를 장기 저장소에 대해서도 실행합니다. 이는 실시간 데이터와 과거 데이터 모두에 대한 쿼리를 가능하게 합니다.
- 중복 제거: 복제로 인해 중복된 데이터를 수신할 수 있는데, Querier는 동일한 나노초 타임스탬프, 레이블 세트 및 로그 메시지를 가진 데이터를 중복 제거하여 최종 쿼리 결과의 정확성을 보장합니다.
- LogQL 쿼리 언어를 사용하여 로그 데이터에 대한 쿼리를 처리한다.
- 아래와 같은 기능을 수행한다.
- Query Frontend
- 로그 스트림이 장기 저장소에 읽어지는 과정
- 로그 데이터를 장기 저장소 백엔드에 저장하고, 필요 시 인메모리 쿼리를 통해 데이터를 빠르게 검색하는 역할을 한다.
- Distributor
- 로그 스트림이 장기 저장소에 저장되는 과정

- LogQL 쿼리 언어를 사용하여 로그 데이터에 대한 쿼리를 처리한다.
- 아래와 같은 기능을 수행한다.
- Query Frontend
- 로그 스트림이 장기 저장소에 읽어지는 과정
- 로그 데이터를 장기 저장소 백엔드에 저장하고, 필요 시 인메모리 쿼리를 통해 데이터를 빠르게 검색하는 역할을 한다.
- Distributor
- 로그 스트림이 장기 저장소에 저장되는 과정
'DevOps > Loki' 카테고리의 다른 글
| Loki에서 Vector 란? (0) | 2025.04.30 |
|---|---|
| LogQL과 구성 요소 (0) | 2025.03.25 |
| LogQL 에서 |= 와 |~ 의 의미 (0) | 2025.03.24 |
| Loki API (0) | 2025.03.22 |
| Loki 란? (0) | 2025.03.22 |